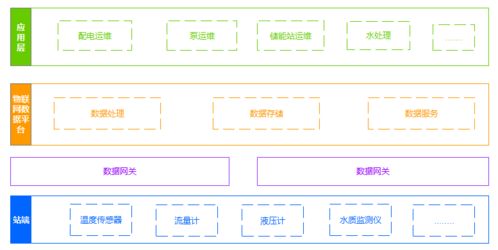
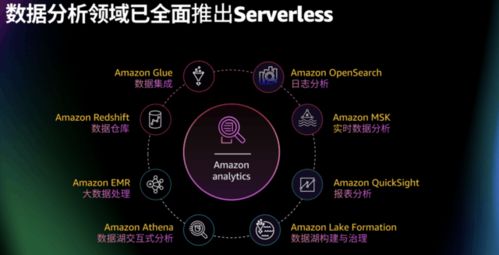
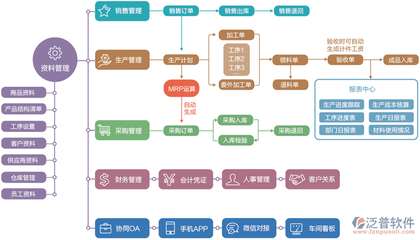
隨著云計算和大數據技術的快速發展,DevOps(開發與運維一體化)理論體系在數據處理服務領域的應用經歷了顯著的演進。這一演進不僅推動數據處理服務從傳統模式向現代化轉型,還深刻影響了企業數據驅動決策的效率與質量。本文將分階段解析DevOps理論體系在數據處理服務中的演進歷程,并探討未來趨勢。
第一階段:傳統數據處理與運維分離的挑戰
在早期,數據處理服務通常采用瀑布式開發模式,開發團隊負責構建數據管道、ETL(提取、轉換、加載)流程,而運維團隊則負責管理服務器、存儲和網絡。這種分離導致數據處理生命周期中存在諸多瓶頸:部署周期長、環境不一致、錯誤難以追蹤。例如,數據處理腳本在開發環境中運行正常,但在生產環境中因依賴項缺失而失敗。數據質量監控和故障恢復主要依賴手動干預,導致數據延遲和可靠性問題。這一階段,DevOps理念尚未普及,數據處理服務往往被視為一次性項目,缺乏持續集成和自動化機制。
第二階段:DevOps理念的引入與自動化實踐
隨著敏捷開發和持續交付理念的興起,DevOps開始應用于數據處理服務。核心變革在于打破開發與運維的壁壘,引入自動化工具鏈。例如,使用Jenkins或GitLab CI/CD實現數據管道的持續集成和部署;通過Docker容器化技術確保環境一致性;借助Ansible或Terraform自動化基礎設施管理。在數據處理場景中,這表現為數據ETL流程的版本控制、自動化測試和監控告警。例如,一個典型的數據處理服務可能包括:代碼提交觸發CI流程,自動運行單元測試和集成測試,部署到預生產環境驗證數據準確性,最終無縫發布到生產環境。這一階段,數據處理服務的迭代速度顯著提升,錯誤率下降,團隊協作效率增強。\n
第三階段:DataOps的興起與DevOps深度融合
隨著數據量的爆炸性增長和實時處理需求的增加,傳統DevOps在數據處理服務中面臨新挑戰,如數據治理、合規性和可觀測性。這催生了DataOps(數據運維)概念,它作為DevOps的擴展,專注于數據流水線的敏捷性和可靠性。DataOps強調數據質量監控、元數據管理和數據血緣追蹤,與DevOps工具鏈深度融合。例如,使用Apache Airflow或dbt(數據構建工具)編排復雜的數據工作流;集成Prometheus和Grafana實現數據流水線的實時監控;通過數據湖或數據網格架構支持分布式數據處理。在這一階段,數據處理服務不再是孤立的管道,而是與業務應用緊密集成的生態系統。企業能夠實現數據的快速實驗、A/B測試和反饋循環,從而加速數據驅動決策。
第四階段:云原生與AI驅動的未來趨勢
當前,DevOps理論體系在數據處理服務中正朝著云原生和AI驅動的方向發展。云原生技術(如Kubernetes和Serverless架構)使數據處理服務更具彈性和可擴展性,同時降低運維成本。AI和機器學習被集成到DevOps流水線中,實現智能監控、自動故障診斷和預測性維護。例如,通過AI算法分析數據流水線的日志和指標,自動識別異常并觸發修復動作;或使用ML模型優化數據分區和緩存策略。隨著數據隱私法規(如GDPR)的強化,DevOps實踐也融入了安全左移(Shift-Left Security)原則,確保數據處理服務從設計階段就符合合規要求。未來,DevOps與DataOps的融合將進一步深化,推動數據處理服務向自治、自適應系統演進。
DevOps理論體系在數據處理服務中的演進,體現了從分離到集成、從手動到自動、從靜態到動態的變革。這一演進不僅提升了數據處理服務的效率與可靠性,還為企業創新提供了堅實的數據基礎。隨著技術發展,DevOps將繼續演化,引領數據處理服務進入更智能、更敏捷的新時代。