在工業自動化與智能制造領域,海量時序數據的實時采集、存儲與分析是支撐企業數字化轉型的核心。華自科技作為國內領先的工業自動化解決方案提供商,其自身生產與運營過程也產生了海量的設備狀態、環境參數、生產日志等時序數據。面對傳統關系型數據庫在處理這類數據時遇到的存儲成本高、查詢效率低、運維復雜等挑戰,華自科技經過深入調研與測試,最終選擇引入時序數據庫TDengine,成功實現了數據處理服務的架構升級。
一、 傳統架構的痛點與選型考量
在華自科技的原有數據平臺中,主要使用傳統關系型數據庫結合部分開源時序方案來處理設備產生的時序數據。隨著接入設備數量的指數級增長,數據體量迅速膨脹,該架構的弊端日益凸顯:
- 服務器資源消耗巨大:為應對寫入與查詢壓力,需要部署大量數據庫服務器和中間件,硬件與運維成本高昂。
- 數據處理性能瓶頸:在高并發寫入和數據聚合分析場景下,響應速度無法滿足實時監控與即時決策的需求。
- 存儲成本高企:原始數據未經深度壓縮,占用大量磁盤空間,長期存儲成本壓力大。
- 系統復雜度高:需要多套系統協同,架構復雜,開發與運維難度大。
基于以上痛點,華自科技對市面上的時序數據庫進行了全面評估。TDengine憑借其專為時序數據設計的存儲引擎、極高的數據壓縮率、內置的緩存與流式計算功能,以及單一二進制文件部署、極簡運維的特性脫穎而出。其創新的“一個設備一張表”數據模型和針對時序場景優化的SQL語法,能夠顯著降低系統復雜度和學習成本。
二、 TDengine的落地實踐與架構優化
華自科技采取了分階段、漸進式的落地策略:
- 試點驗證:首先選取一個典型的生產線監控場景進行試點,將設備傳感器數據接入TDengine集群。初步結果令人振奮:相比原方案,寫入吞吐量提升超過10倍,復雜聚合查詢響應時間從秒級降至毫秒級。
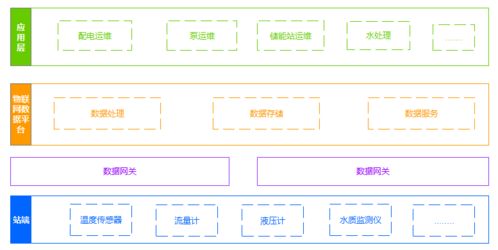
- 架構重構:在試點成功的基礎上,開始系統性重構數據處理服務層。新的架構以TDengine集群為核心,直接接收來自邊緣網關或消息隊列的時序數據流。利用TDengine的超級表功能對同類設備進行高效建模,通過標簽實現靈活的元數據管理和多維查詢。
- 服務整合:利用TDengine內建的連續查詢功能替代了部分外部的流處理任務,簡化了架構。其強大的時間窗口聚合函數和向下采樣功能,使得應用層能夠輕松獲取不同時間精度的匯總數據,直接服務于監控大屏、統計分析報表和預警系統。
- 降本增效:TDengine極高的壓縮比(在華自科技的實際場景中達到10:1以上)使得存儲相同數據量所需的磁盤空間大幅減少。更重要的是,由于其卓越的單機性能,華自科技成功將數據處理層的服務器節點數量減少了一半,直接大幅降低了硬件采購成本、機房空間占用和電力消耗。
三、 實踐成效與未來展望
TDengine在華自科技的落地,帶來了立竿見影的收益:
- 成本顯著降低:服務器硬件數量減半,長期存儲成本下降超過60%。
- 性能大幅提升:數據處理服務端到端延遲降低80%,支撐了更精細的實時監控與更快的業務洞察。
- 運維極大簡化:從原先維護多套復雜系統,轉變為集中運維一個高性能、高可用的TDengine集群,運維效率提升,人力投入減少。
- 開發更敏捷:簡潔的SQL接口和清晰的數據模型,讓應用開發團隊能夠更專注于業務邏輯,開發效率提升。
華自科技計劃進一步深化TDengine的應用:
- 將更多業務系統的時序數據(如能源管理、質量追溯)遷移至TDengine平臺,構建統一的企業級時序數據湖。
- 探索利用TDengine與AI框架的結合,對設備時序數據進行深度挖掘,實現預測性維護和工藝優化。
- 借助TDengine的云原生版本,探索混合云部署方案,以更靈活地應對業務增長和全球化布局的需求。
華自科技的實踐表明,針對特定的數據范式選擇專精的數據庫技術,是數字化轉型中實現降本增效的關鍵路徑。TDengine以其卓越的時序數據處理能力,不僅幫助華自科技解決了服務器資源激增的燃眉之急,更通過架構的簡化與性能的飛躍,為其智能制造與數據驅動戰略夯實了堅實的數據基石。這一“服務器減半,效能倍增”的成功案例,也為廣大工業制造企業提供了可借鑒的時序數據管理新范式。